In large-scale industrial documents with scanned images, complex layouts, and multiple pages, the effectiveness of retrieval-augmented generation (RAG) is highly dependent on chunking quality. Existing text-centric chunkers overlook the visual and structural cues present in real-world documents, leading to redundant or ambiguous chunks that impair retrieval and answer accuracy.
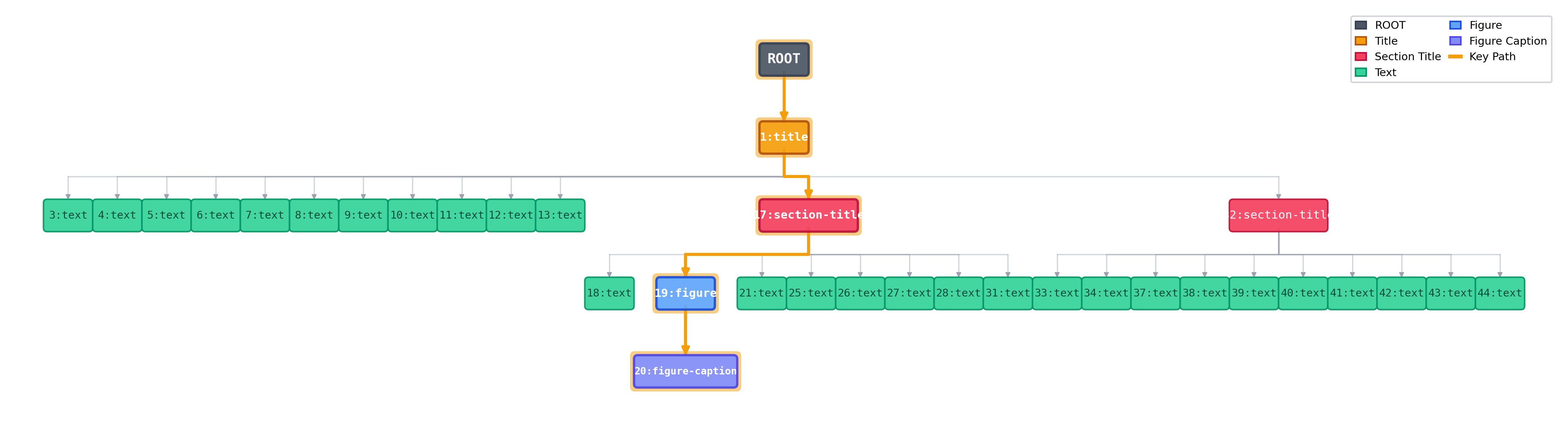
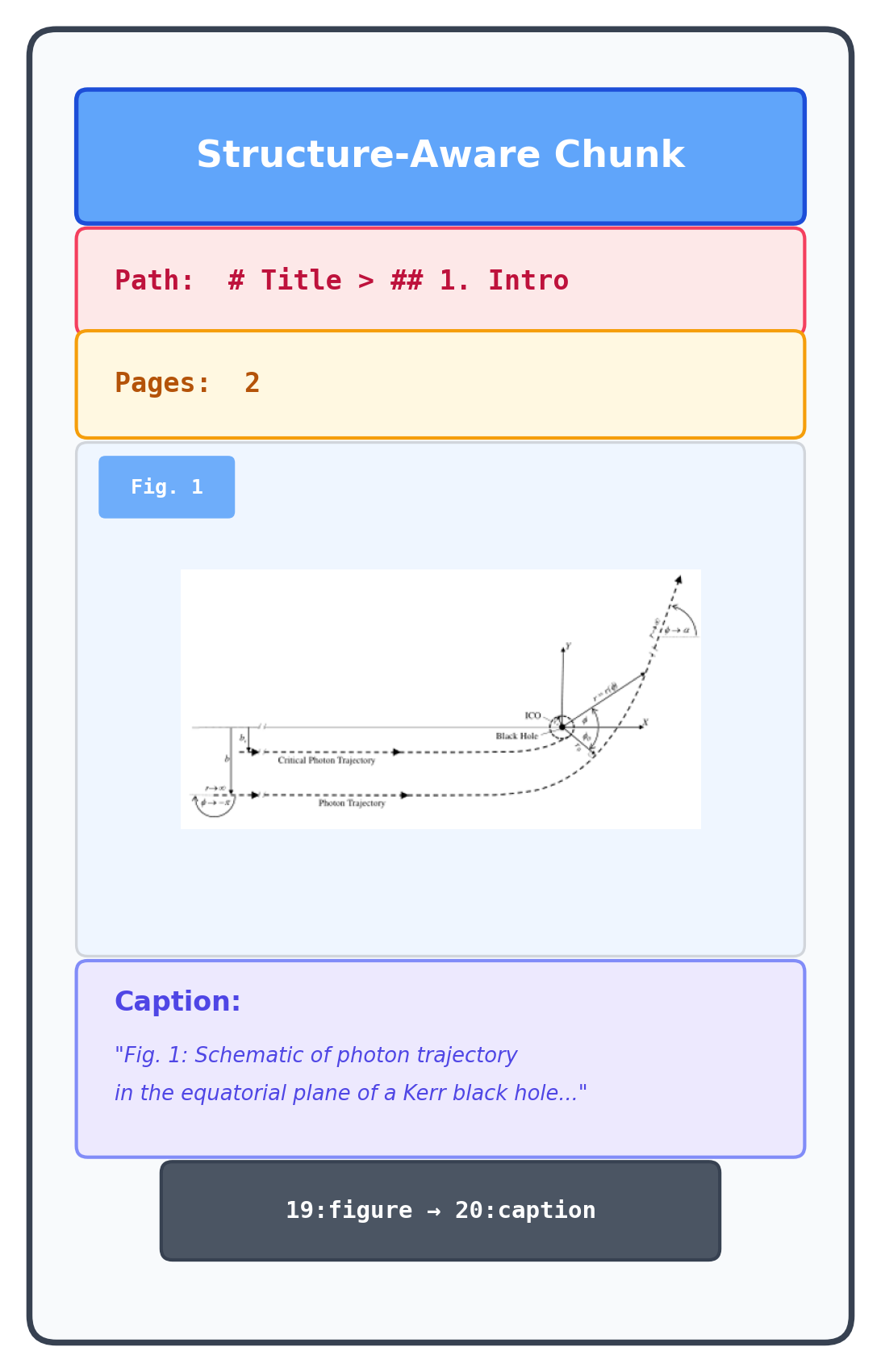
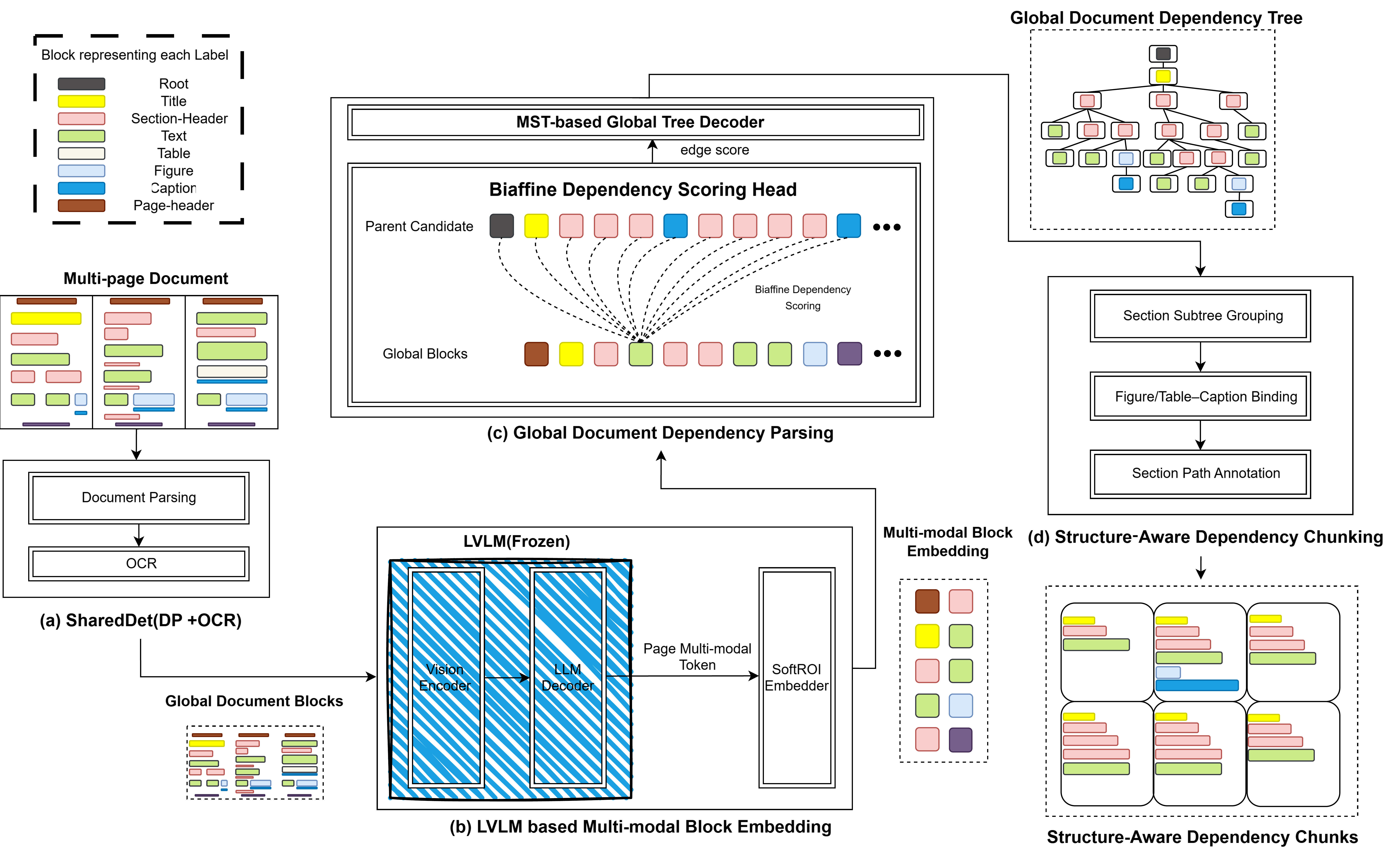
We propose M3DocDep, which integrates (i) SharedDet for normalizing document parsing and OCR outputs into a document-level frame, (ii) multi-modal block embeddings with boundary-aware SoftROI, (iii) global document-tree reconstruction via biaffine scoring, and (iv) structure-aware dependency chunking that preserves boundaries and reduces redundancy.
M3DocDep achieves consistent gains across both Document Hierarchical Parsing (DHP) and corpus-level RAG evaluations, improving STEDS by +28.5–39.6%, retrieval nDCG by +1.1–15.3%, and QA ANLS by +4.5–15.3%. These results demonstrate that modeling document-level dependencies with multi-modal, structure-aware chunking improves RAG performance on long, multi-page industrial documents.